Articles in this series
- Part I. Iterative Servers
- Part II. Forking Servers
- Part III. Pre-forking Servers
- Part IV. Threaded Servers
- Part V. Pre-threaded Servers
- Part VI: poll-based server
- Part VII: epoll-based server
On HackerNews
There are several interesting takeaways from the HackerNews thread for this article series. Do check it out.
Web apps are the staple of consumers and enterprises. Among the many existing protocols that are used to move and make sense of bits, HTTP has an overwhelming mind share. As you encounter and learn the nuances of web application development, most of you might pay very little attention to the operating system that finally runs your applications. The separation of Dev and Ops only made this worse. But with the DevOps culture becoming common place and developers becoming responsible for running their apps in the cloud, it is a clear advantage to better understand backend operating system nitty-gritty. You don’t really have to bother with Linux and how your backend will scale if you are deploying your backend as a system for personal use or for use by a few concurrent users. If you are trying to deploy for thousands or tens of thousands of concurrent users, however, having a good understanding of how the operating system figures out in your whole stack will be incredibly useful.
The constraints we are up against in the web services we write are very similar to those in other applications that are required to make a web service or application work. Be those load balancers or the database servers. All these classes of applications have similar challenges in high-performance environments. Understanding these fundamental constraints and how to work around them will in general make you appreciate what performance and scalability of your web applications or services are up against.
I am writing this series in response to the questions I get asked by young developers who want to become well–informed system architects. Without diving down into the basics of what makes Linux applications tick and the different ways of structuring Linux or Unix network applications, it is not possible to gain a through and clear understanding of Linux application performance. While there are many types of Linux applications, what I want to explore here are Linux networking–oriented applications as opposed to say, a desktop application like a browser or a text editor. This is because the audience for this series are web services/application developers and architects who want to understand how Linux or Unix applications work and how to structure these services for high performance.
Linux is the server operating system and more often than not, your applications probably run on Linux finally. Although I say Linux, most of the time you can safely assume I also include other Unix–like operating systems in general. However, I haven’t extensively tested the accompanying code on other Unix–like systems. So, if you are interested in FreeBSD or OpenBSD, your mileage may vary. Where I attempt anything Linux-specific, I’ve done my best to point it out.
While you can certainly use this knowledge to choose the best possible structure for a new network application you want to write from scratch, you might not be firing up your favorite text editor and writing a web server in C or C++ to solve the problem of having to deliver the next business app in your organization. That might be a guaranteed way to get yourself fired. Having said that, knowing these application structures will help you tremendously in choosing one among a few existing applications, if you know how they are structured. After understanding this article series, you will be able to appreciate process–based vs. thread–based vs. event–based systems. You will get to understand and appreciate why Nginx performs better than Apache httpd or why a Tornado based Python application might be able to serve more concurrent users compared to a Django based Python application.
ZeroHTTPd: A learning tool
ZeroHTTPd is a web server I wrote from scratch in C as a teaching tool. It has no external dependencies, including for Redis access. We roll our own Redis routines–read more below.
While we could talk a whole lot of theory, there is nothing like writing code, running it, benchmarking it to compare each of server architectures we evolve. This should cement your understanding like no other method. To this end, we will develop a simple web server called ZeroHTTPd using process–based, thread–based and event–based models. We will benchmark our each of these servers and see how they perform relative to one another. ZeroHTTPd is a simple–as–possible HTTP server written from scratch in pure C with no external library dependencies. It is implemented in a single C file. For event-based servers, I include uthash, an excellent hash table implementation, which is comes in a single header file. Otherwise, there are no dependencies and this is to keep things simple.
I’ve heavily commented the code to aid understanding. ZeroHTTPd is also a bare minimal web development framework apart from being a simple web server written in a couple of hundred lines of C. It doesn’t do a lot. But, it can server static files and very simple “dynamic” pages. Having said this, ZeroHTTPd is well-suited for you to understand how to architect your Linux applications for high-performance. At the end of the day, most web services wait around for requests, look into what that request is and process them. This is exactly what we will be doing with ZeroHTTPd as well. It is a learning tool, not something you’ll use in production. It is also not going to win awards for error handling, security best practices (oh yes, I’ve used strcpy) or for clever tricks and shortcuts of the C language, of which there are several. But, it’ll hopefully serve its purpose well (pun unintended).
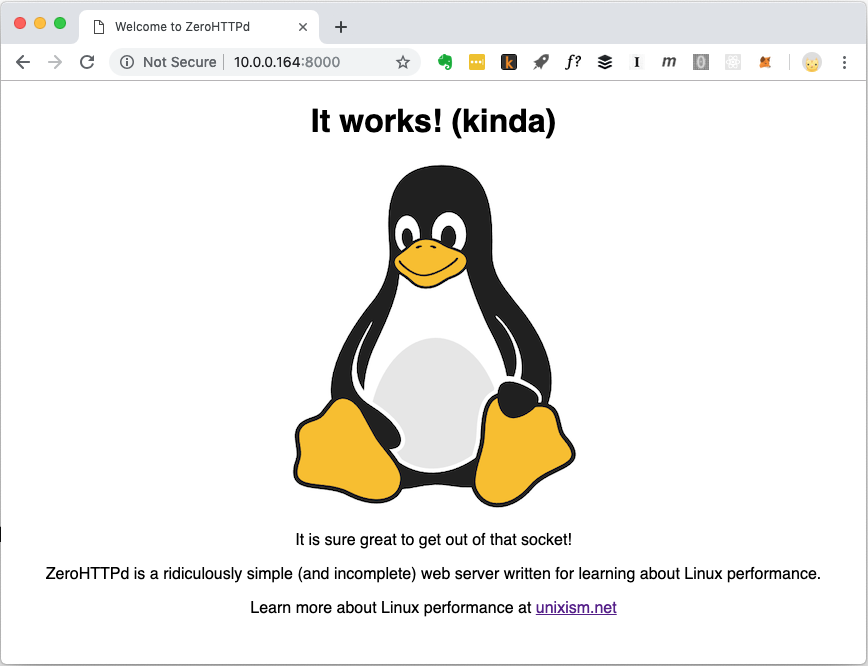
The Guestbook App
Modern web applications hardly serve just static files. They have complex interactions with various databases, caches, etc. To that end, we build a simple web app named “Guestbook” that lets guests lovingly leave their name and remarks. Guestbook also lists remarks previously left by various guests as well. There is also a visitor counter towards the bottom of the page.
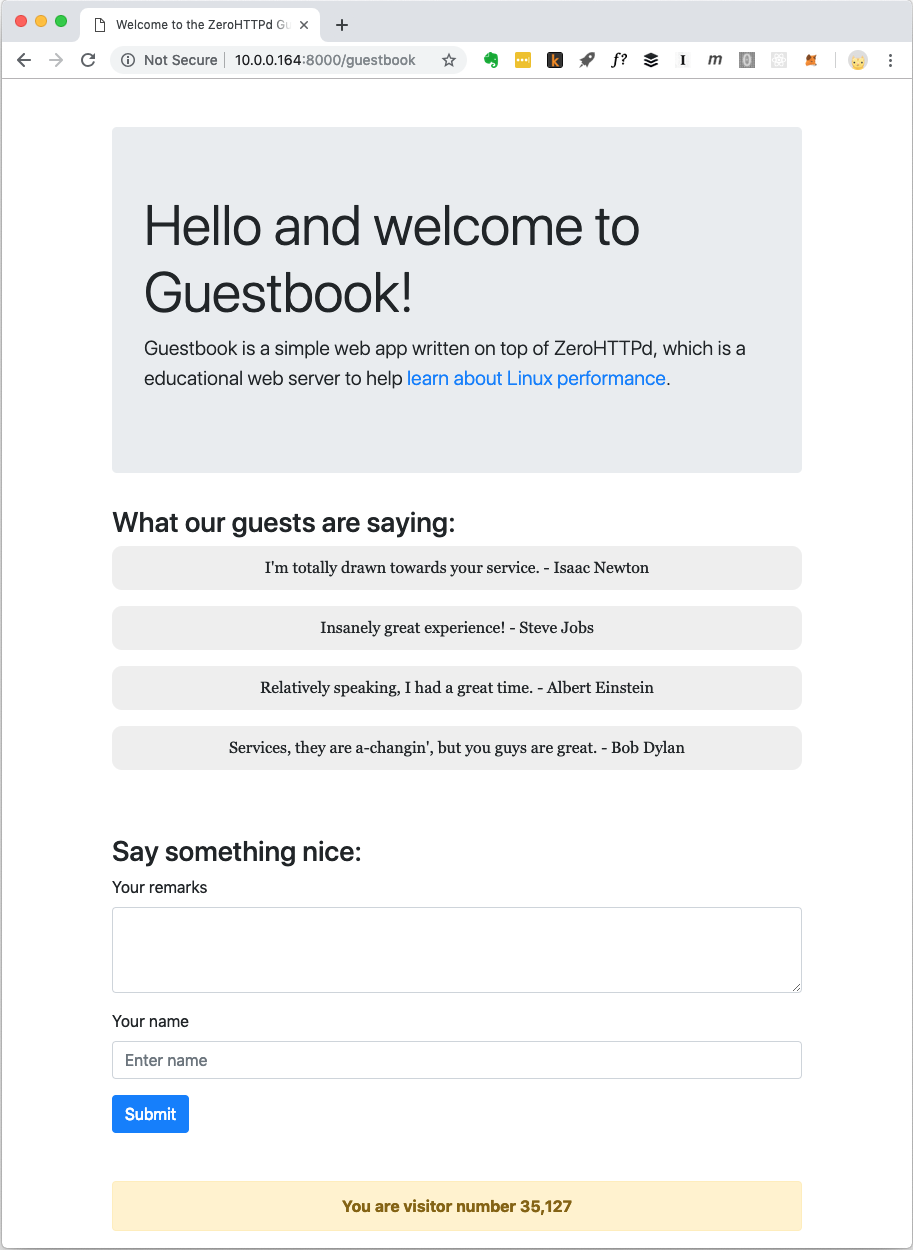
We store the visitor counter and the guest book entries in Redis. To talk to Redis, we do not depend on an external library. We have our own custom C routines to talk to Redis. I’m not big fan of rolling out your own stuff when you can use something that is already available and well tested. But the goal of ZeroHTTPd is to teach Linux performance and accessing external services while in the middle of serving an HTTP request has a huge implications as far as performance goes. We need to be in full control of the way we talk to Redis in each of the server architectures we are building. While in one architecture we use blocking calls, in others we use event-based routines. Using an external Redis client library won’t allow us this control. Also, we will be implementing our own Redis client only to the extent we will use Redis (Getting, setting and incrementing a key. Getting and appending to an array). Moreover, the Redis protocol is super elegant and simple. Something to even learn about deliberately. The very fact that you can implement a super-fast protocol that does its job in about 100 lines of codes goes to say a lot about how well thought out the protocol is.
The following figure illustrates the steps we follow in order to get the HTML ready to serve when a client (browser) requests the /guestbookURL.

When a Guestbook page needs to be served, there is one file-system call to read the template into memory and three network-related calls to Redis. The template file has most of the HTML content that makes up the Guestbook page you see in the screenshot above. It also has special placeholders where the dynamic part of the content which comes from Redis like guest remarks and the visitor counter go. We fetch these from Redis, replace these for the placeholders in the template file and finally, the fully formed content is written out to the client. The third call to Redis could have been avoided since Redis returns the new value of any incremented key. However, for our purposes, as we move our server to asynchronous, event-based architectures, having a server that is busy blocking on a bunch of network calls is a good way to learn about things. So, we discard the return value that Redis returns when we increment the visitor count and read it back in a separate call.
ZeroHTTPd Server Architectures
We will build ZeroHTTPd, retaining the same functionality, using 7 different architectures:
- Iterative
- Forking (one child process per request)
- Pre-forked server (pre-forked processes)
- Threaded (one thread per request)
- Pre-threaded (threads pre-created)
poll()-basedepollbased
We shall also measure the performance of each architecture loading them each with 10,000 HTTP requests. However, as we move on to comparisons with architectures that can handle a lot more concurrency, we will switch to testing with 30,000 requests. We test 3 times and consider the average.
Testing Methodology
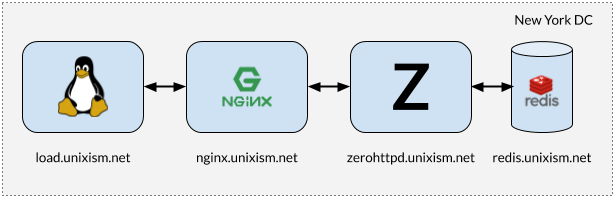
It is important that these tests not be run with all components on the same machine. If that is done, the operating system will have the extra overhead of scheduling between all those components, as they vie for CPU. Measuring operating system overhead with each of the chosen server architectures is one of the most important aims of this exercise. Adding more variables will be detrimental to the process. Hence, a setup described in the illustration above will work best.
Here is what each of these servers do:
- load.unixism.net: This is where we run
ab, the Apache Benchmark utility, which generates the load we need to test our server architectures. - nginx.unixism.net: At times we may want to run more than one instance of our server program. So, we use a suitably configured Nginx server as a load balancer to spread the load coming in from
abon to our server processes. - zerohttpd.unixism.net: This is where we run our server programs, which are based on the 7 different architectures listed above, one architecture at a time.
- redis.unixism.net: This server runs the Redis daemon which stores the guest remarks and the visitor counter.
All servers have a single CPU core. The idea is to see how much performance we can wring out of it with each of our server architectures. Since all of our server programs are measured against the same hardware, it acts as the baseline against which we measure the relative performance or each of our server architectures. My testing setup consisted of virtual servers rented from Digital Ocean.
What are we measuring?
There are many things we can measure. However, given a certain amount of compute resources, we want to see how much performance we can squeeze out of each architecture at various levels of increasing concurrency. We test with up to 15,000 concurrent users.
Test Results
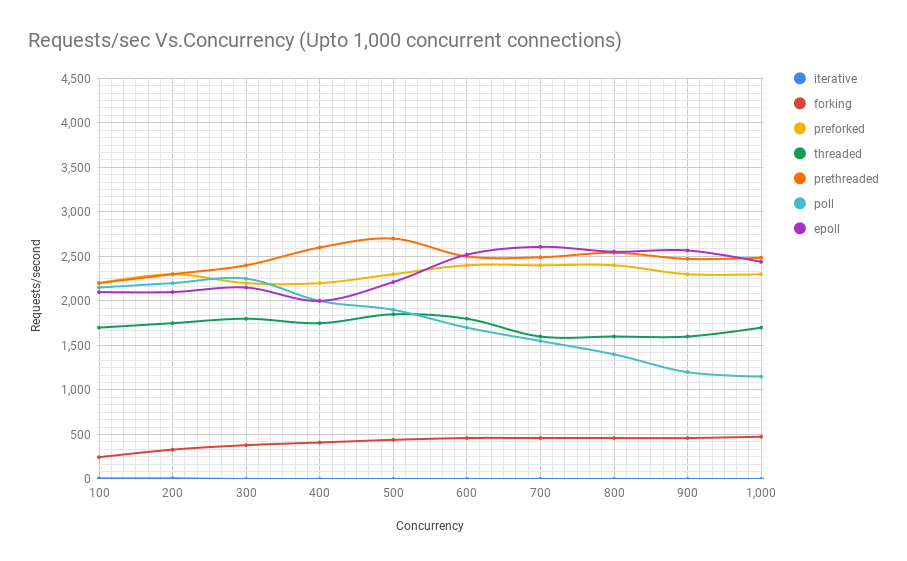
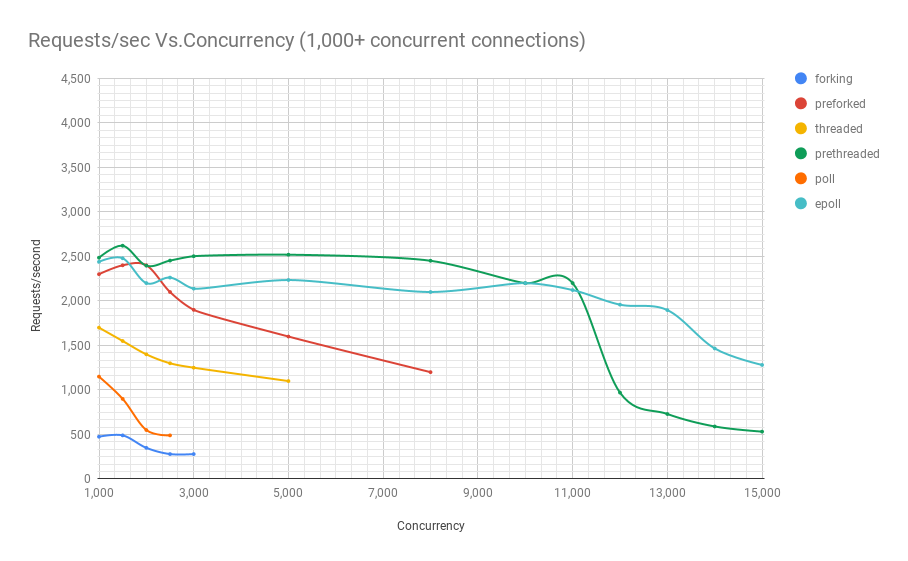
The following chart shows how servers employing different process architectures perform when subjected to various concurrency levels. In the y-axis we have requests/sec and in the x-axis we have concurrent connections.
Click to view full size
Click to view full size
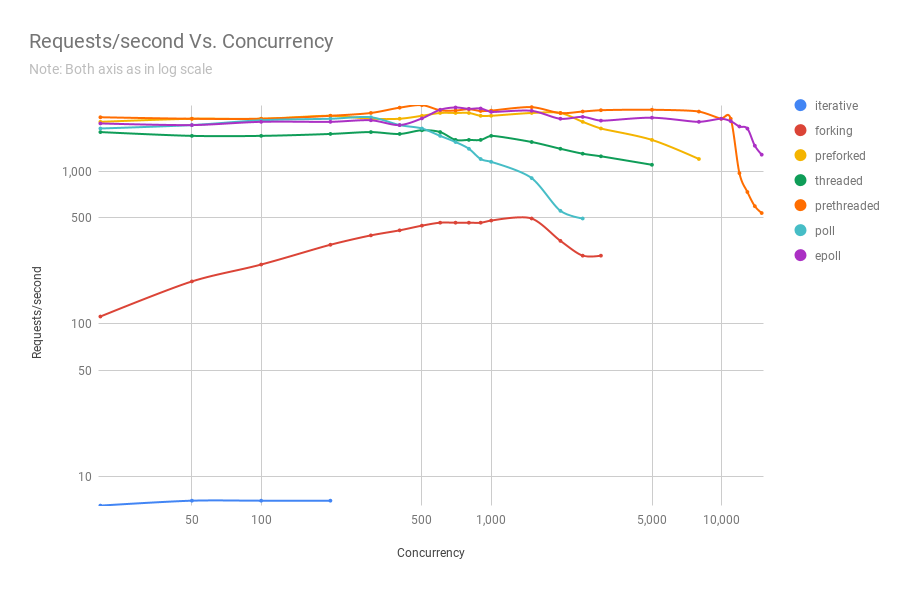
Click to view full size
Here is a table that with the numbers laid out
|
|
|||||||
| concurrency | iterative | forking | preforked | threaded | prethreaded | poll | epoll |
| 20 | 7 | 112 | 2,100 | 1,800 | 2,250 | 1,900 | 2,050 |
| 50 | 7 | 190 | 2,200 | 1,700 | 2,200 | 2,000 | 2,000 |
| 100 | 7 | 245 | 2,200 | 1,700 | 2,200 | 2,150 | 2,100 |
| 200 | 7 | 330 | 2,300 | 1,750 | 2,300 | 2,200 | 2,100 |
| 300 | – | 380 | 2,200 | 1,800 | 2,400 | 2,250 | 2,150 |
| 400 | – | 410 | 2,200 | 1,750 | 2,600 | 2,000 | 2,000 |
| 500 | – | 440 | 2,300 | 1,850 | 2,700 | 1,900 | 2,212 |
| 600 | – | 460 | 2,400 | 1,800 | 2,500 | 1,700 | 2,519 |
| 700 | – | 460 | 2,400 | 1,600 | 2,490 | 1,550 | 2,607 |
| 800 | – | 460 | 2,400 | 1,600 | 2,540 | 1,400 | 2,553 |
| 900 | – | 460 | 2,300 | 1,600 | 2,472 | 1,200 | 2,567 |
| 1,000 | – | 475 | 2,300 | 1,700 | 2,485 | 1,150 | 2,439 |
| 1,500 | – | 490 | 2,400 | 1,550 | 2,620 | 900 | 2,479 |
| 2,000 | – | 350 | 2,400 | 1,400 | 2,396 | 550 | 2,200 |
| 2,500 | – | 280 | 2,100 | 1,300 | 2,453 | 490 | 2,262 |
| 3,000 | – | 280 | 1,900 | 1,250 | 2,502 | wide variations | 2,138 |
| 5,000 | – | wide variations | 1,600 | 1,100 | 2,519 | – | 2,235 |
| 8,000 | – | – | 1,200 | wide variations | 2,451 | – | 2,100 |
| 10,000 | – | – | wide variations | – | 2,200 | – | 2,200 |
| 11,000 | – | – | – | – | 2,200 | – | 2,122 |
| 12,000 | – | – | – | – | 970 | – | 1,958 |
| 13,000 | – | – | – | – | 730 | – | 1,897 |
| 14,000 | – | – | – | – | 590 | – | 1,466 |
| 15,000 | – | – | – | – | 532 | – | 1,281 |
You can see from the chart and table above that beyond 8,000 concurrent requests we only have 2 contenders: pre-threaded and epoll. In fact, our poll-based server fares worse than the threaded server, which comfortably beats the former in performance even at the same concurrency levels. The prethreaded server architecture giving the epoll-based server a good run for its money is a testament to how well the Linux kernel handles scheduling of a very large number of threads.
ZeroHTTPd Source Code Layout
You can find the source code for ZeroHTTPd here. Each server architecture gets its own directory.
ZeroHTTPd
│
├── 01_iterative
│ ├── main.c
├── 02_forking
│ ├── main.c
├── 03_preforking
│ ├── main.c
├── 04_threading
│ ├── main.c
├── 05_prethreading
│ ├── main.c
├── 06_poll
│ ├── main.c
├── 07_epoll
│ └── main.c
├── Makefile
├── public
│ ├── index.html
│ └── tux.png
└── templates
└── guestbook
└── index.html
In the top level directory, apart from the 7 folders that hold the code for ZeroHTTPd based on the 7 different architectures we discuss, there are 2 other directories there. The “public” and “templates” directories. The “public/” directory contains an index file and an image that you see in the screenshot. You can put other files and folders in here and ZeroHTTPd should serve those static files without problems. When the path component entered in the browser matches a path inside the “public” folder, ZeroHTTPd will look for an “index.html” file in that directory before giving up. Our Guestbook app, which is accessed by going to the path /guestbook, is a dynamic app, meaning that its content is dynamically generated. It has only one main page and content for that page is based on the file “templates/guestbook/index.html”. It is easy to add more dynamic pages to ZeroHTTPd and extend it. The idea is that users can add more templates inside this directory and extend ZeroHTTPd as needed.
To build all 7 servers, all you need to do it run “make all” from the top level directory and all 7 servers are built and placed in the top level directory. The executables expect the “public” and “templates” directories in the same directory they are run from.
Linux APIs
If you don’t understand the Linux API well, you should still be able to follow this series and get a decent enough understanding. I however, do recommend you read more about the Linux programming API. There are innumerable resources to help you out in this regard and that is out of scope as far as this article series goes. Although we will touch over several of Linux’s API categories, our focus will be in mainly in the areas of processes, threads, events and networking. If you don’t know the Linux API well, I encourage you to read the man pages for the system calls and library functions used apart from reading books and articles on their usage.
Performance and scalability
One thought about performance and scalability. There is no relationship between them, theoretically speaking. You can have a web service that performs really well, responds within a few milliseconds, but does not scale at all. Similarly, there can be a badly performing web application that takes several seconds to respond, but scales to handle tens of thousands of concurrent users. Having said that, the combination of high-performance, highly scalable services is very powerful. High-performance applications use resources sparingly in general and are thus efficient at serving more concurrent users per server, driving down costs, which is a good thing.
CPU and I/O–bound tasks
Finally, there are always only two possible types of tasks in computing: I/O bound and CPU bound. Getting requests over the internet (network I/O), serving files (network and disk I/O), talking to a database (network and disk I/O) are all I/O bound activities. Several types of DB queries can use a bit of CPU, though (sorting, calculating the mean of a million results, etc). Most of the web applications you will build will be I/O bound and the CPU will rarely be used to its full capacity. When you see a lot of CPU being used in a I/O bound application, it most likely points to poor application architecture. This could mean that the CPU essentially is being spent in process management and context switching overhead–and that’s not exactly very useful. If you are doing things like heavy image processing, audio file conversion or machine learning inference, then your application will tend to be CPU bound. However, for the majority of applications, this won’t be the case.
Special Thanks
Writing an article series that is tens of thousands of words becomes easy with help from reviewers. Thanks go out to Vijay Lakshminarayanan and Arun Venkataswamy for spending their time reviewing this series and suggesting corrections to several obvious and not-so-obvious problems.
Go deeper into a server architecture
- Part I. Iterative Servers
- Part II. Forking Servers
- Part III. Pre-forking Servers
- Part IV. Threaded Servers
- Part V. Pre-threaded Servers
- Part VI: poll-based server
- Part VII: epoll-based server
About me
My name is Shuveb Hussain and I’m the author of this Linux-focused blog. You can follow me on Twitter where I post tech-related content mostly focusing on Linux, performance, scalability and cloud technologies.
Comments
13 responses to “Linux Applications Performance: Introduction”
[…] This chapter is part of a series of articles on Linux application performance. […]
[…] This chapter is part of a series of articles on Linux application performance. […]
[…] This chapter is part of a series of articles on Linux application performance. […]
[…] This chapter is part of a series of articles on Linux application performance. […]
[…] This chapter is part of a series of articles on Linux application performance. […]
[…] This chapter is part of a series of articles on Linux application performance. […]
[…] This chapter is part of a series of articles on Linux application performance. […]
[…] Source: unixism.net […]
[…] Articles in this series Part I. Iterative Servers Part II. Forking Servers Part III. Pre-forking Servers Part IV. Threaded Servers Part V. Pre-threaded Servers Part VI: poll-based server Part VII: epoll-based server Web apps are the staple of consumer…Read More […]
[…] By news.tkok.org 3rd June 2019 No Comments […]
[…] Linux Applications Performance: Introduction – Unixism […]
[…] 元記事: Linux Applications Performance: Introduction - Unixism […]
[…] for readv() and writev(), you have the capability to write a simple web server! This web server is based on code I wrote for ZeroHTTPd, a program that features in an article series I wrote to explore various Linux process models and […]