This chapter is part of a series of articles on Linux application performance.
The iterative network server is one of the earliest programs you might have written if you ever took a course or read a book on network programming. These type of servers are not very useful except for learning network programming or in rare cases where traffic and concurrency are expected to be low. An iterative server, as its name suggests, serves one client after the other, in succession usually running in a single process. While a client is being served, if other requests arrive, they are queued by the operating system and they wait until the server is done with the current client being served after which it is ready to pick up the next client. An iterative server thus, exhibits no concurrency. It serves exactly one client at a time.
ZeroHTTPd workings
Although this chapter/article covers the mechanics of how an iterative server works, it also covers how ZeroHTTPd, a simple web server works. This includes details of how it handles the HTTP protocol in general. In other articles in this series, we won’t go into these details and will stick to the specific changes we make to the server architecture in order to better support concurrency. We won’t cover the more generic aspects of ZeroHTTPd since we will be covering them here already. So, if you are interested in how the HTTP handling aspects of ZeroHTTPd work, this is the article in the series you should be reading.
Compiling and running ZeroHTTPd
Clone the ZeroHTTPd Git repo and change into the zerohttpd directory. You can now compile and run ZeroHTTPd. Use the following commands to compile and run the iterative server. You can press Ctrl+c at the terminal to stop the server. It is also assumed that you are running the Redis server locally.
➜ zerohttpd git:(master) ✗ make all gcc -o iterative 01_iterative/main.c gcc -o forking 02_forking/main.c gcc -o preforked 03_preforked/main.c gcc -o threaded 04_threaded/main.c -lpthread gcc -o prethreaded 05_prethreaded/main.c -lpthread gcc -o poll 06_poll/main.c gcc -o epoll 07_epoll/main.c ➜ zerohttpd git:(master) ✗ ./iterative Connected to Redis server@ 127.0.0.1:6379 ZeroHTTPd server listening on port 8000
I shall now walk you through the source code for the iterative version of ZeroHTTPd, our super simple web server that shall serve as our leaning tool. Like any C program, ZeroHTTPd starts life with the main() function and here it is:
int main(int argc, char *argv[])
{
int server_port;
if (argc > 1)
server_port = atoi(argv[1]);
else
server_port = DEFAULT_SERVER_PORT;
if (argc > 2)
strcpy(redis_host_ip, argv[2]);
else
strcpy(redis_host_ip, REDIS_SERVER_HOST);
int server_socket = setup_listening_socket(server_port);
connect_to_redis_server();
/* Setting the locale and using the %' escape sequence lets us format
* numbers with commas */
setlocale(LC_NUMERIC, "");
printf("ZeroHTTPd server listening on port %d\n", server_port);
signal(SIGINT, print_stats);
enter_server_loop(server_socket);
return (0);
}
To all versions of ZeroHTTPd, you can optionally pass 2 command line arguments. The first one being the port on which you want the server to listen and the second being the Redis server IP address to which you want ZeroHTTPd to connect to. If one or either of these command line parameters are not provided, defaults are used. The default server port being 8,000 and the Redis server, 127.0.0.1, which is your local machine. Let’s now move on to setup_listening_socket(), which is the first function main() calls.
int setup_listening_socket(int port) {
int sock;
struct sockaddr_in srv_addr;
sock = socket(PF_INET, SOCK_STREAM, 0);
if (sock == -1)
fatal_error("socket()");
int enable = 1;
if (setsockopt(sock,
SOL_SOCKET, SO_REUSEADDR,
&enable, sizeof(int)) < 0)
fatal_error("setsockopt(SO_REUSEADDR)");
bzero(&srv_addr, sizeof(srv_addr));
srv_addr.sin_family = AF_INET;
srv_addr.sin_port = htons(port);
srv_addr.sin_addr.s_addr = htonl(INADDR_ANY);
/* We bind to a port and turn this socket into a listening
* socket.
* */
if (bind(sock,
(const struct sockaddr *)&srv_addr,
sizeof(srv_addr)) < 0)
fatal_error("bind()");
if (listen(sock, 10) < 0)
fatal_error("listen()");
return (sock);
}
Line #5 creates the socket, which is like a pipe from which the server can read and write. We specify the protocol family and type. On line #10, we tell the operating system it is OK to reuse this socket’s address. Remember, we are binding to port 8,000. Without this option, if you ran the server, stopped it and then restarted it immediately after having served at least one client, it won’t bind back on port 8,000 since any client connections will go into a TIME_WAIT state while the OS waits for any potential leftover data to be transferred. This will prevent quick restarts. You can try commenting out the calls to setsocketopt() and its related fatal_error() call, recompile and run. Now, open a browser tab and point it to http://localhost:8000. Close the tab, stop the server by hitting Ctrl+c and restart it again. You should see:
bind(): Address already in use
This is the OS waiting while the client (browser) connection you just established times out. You can check out sockets in the TIME_WAIT state using the netstat utility. I leave that as an exercise for you, the reader. Setting the SO_REUSEADDR option on the socket lets the operating system reuse the address and bind(), which we will discuss next, will succeed.
On lines 15-18, we describe the socket’s address. Every socket address has two associated pieces of information: the address and the port. Think of a socket’s address as a large locker panel and the port as a particular locker. The server is the locker panel. If the server has more than one network interface with its own unique address (a network card is a network interface, for example), you can specify which particular address you want to bind to. In our case, by specifying INADDR_ANY, we bind to all available interfaces. localhost or 127.0.0.1 is a special address that refers to the local interface, which is the same host on which the program is running. You might already know this.
The bind() system call on line #23 binds the identity we just created (the address and the port) to a socket. This gives the socket an address and this allows clients to reach it. It is bind() and listen() system calls that turn a program into a network server.
The listen() system call on line #28 converts this socket into a listening socket. The queue length, which determines the number of clients that can wait until their request is accepted is a parameter of the listen() system call. While a large number can be specified, most operating systems will silently truncate this number to some internal limit. On Linux by default, this number is 128 and you can change this number by writing a new limit into /proc/sys/net/core/somaxconn.
Our server socket is now setup and is listening on all network interfaces on the machine on which it is running on port 8,000.
void enter_server_loop(int server_socket)
{
struct sockaddr_in client_addr;
socklen_t client_addr_len = sizeof(client_addr);
while (1)
{
int client_socket = accept(
server_socket,
(struct sockaddr *)&client_addr,
&client_addr_len);
if (client_socket == -1)
fatal_error("accept()");
handle_client(client_socket);
close(client_socket);
}
}
Let us now turn our attention to the enter_server_loop() function. The main action is in the while(1) loop. Whenever accept() is called on a listening socket, it blocks until clients connect to it. Whenever a client connects to our server, accept() returns the client socket which we can use with the read() and write() system calls, thus writing to and reading from the client. This client socket which accept() returns, we pass it to the handle_client() function, which handles the HTTP protocol with the help of other functions as we will see in the following sections. When I first started leaning network programming years ago, I thought, if you treated the networking related system calls like English verbs, listen() should have been the system call that should really block. But all it does is convert a socket into a listening socket. It is the accept() call that really blocks waiting to accept connections from clients. So, there’s that.
To understand how HTTP works, it is best to take a look at a session in action. It is quite simple, really. Here, I’ve run the curl command with the -v switch which turns on verbose mode so that you can see what transpires on the wire.
➜ ~ curl -v http://localhost:8000/
* Trying 127.0.0.1...
* TCP_NODELAY set
* Connected to localhost (127.0.0.1) port 8000 (#0)
> GET / HTTP/1.1
> Host: localhost:8000
> User-Agent: curl/7.58.0
> Accept: */*
>
* HTTP 1.0, assume close after body
< HTTP/1.0 200 OK
< Server: zerohttpd/0.1
< Content-Type: text/html
< content-length: 611
<
<!DOCTYPE html>
<html lang="en">
<head>
<title>Welcome to ZeroHTTPd</title>
<style>
body {
font-family: sans-serif;
margin: 15px;
text-align: center;
}
</style>
</head>
<body>
<h1>It works! (kinda)</h1>
<img src="tux.png" alt="Tux, the Linux mascot">
<p>It is sure great to get out of that socket!</p>
<p>ZeroHTTPd is a ridiculously simple (and incomplete) web server written for learning about Linux performance.</p>
<p>Learn more about Linux performance at <a href="https://unixism.net">unixism.net</a></p>
</body>
* Closing connection 0
</html>%
The lines starting with a * are “comments” by curl. The lines starting with a > are part of the request curl sent to our server and the lines starting with < are part of the response it gets back from our server, ZeroHTTPd. Finally, we see the content sent back, which is from the index.html file. Since this is just text and is human readable, you can see that it is all quite simple.
An HTTP request consists of multiple lines. Each line is called an HTTP header. Users sitting at browsers want to see content transferred by HTTP and that is the primary purpose of the protocol. The underlying conversation “spoken” between the client and the server happens mostly via these HTTP “headers”. The main part of the request, as far as ZeroHTTPd is concerned is the first header, which has the HTTP method and the name of resource the client wants. This resource could be a static file or some dynamic content. You can see that the very first line of the request is GET / HTTP/1.1. In ZeroHTTPd, we cheat. We only care about the first line of the request. All other headers, we read and discard. In a more serious web server I don’t see how this can be a good thing! The HTTP protocol often has very important information in these headers and no serious web server worth its salt should be ignoring these like we do. Each header ends with a \r\n (carriage return and line feed) and the server knows that the client is done sending headers when there is an empty line by itself just containing \r\n.
void handle_client(int client_socket)
{
char line_buffer[1024];
char method_buffer[1024];
int method_line = 0;
while (1)
{
get_line(client_socket, line_buffer, sizeof(line_buffer));
method_line++;
unsigned long len = strlen(line_buffer);
/*
The first line has the HTTP method/verb. It's the only
thing we care about. We read the rest of the lines and
throw them away.
*/
if (method_line == 1)
{
if (len == 0)
return;
strcpy(method_buffer, line_buffer);
}
else
{
if (len == 0)
break;
}
}
handle_http_method(method_buffer, client_socket);
}
We call the get_line()function, which reads the client socket character-by-character until it sees the \r\n sequence. This is a particularly inefficient way to read a socket, but in the interest of simplicity, we will forgive ourselves, unlike we do in real life. A better way to do it might be to read the request in chunks and then parse it like real web servers do. But like I said, ZeroHTTPd’s goals are different and we want to keep things simple. Each line is read into the array line_buffer. When we know it is the first line, which is expected to have the GET or other HTTP method request details, we save that header in the method_buffer array. The reason we’ve named the buffer “method_buffer” is because HTTP defines these various “verbs” (GET, POST, DELTE, etc) which tell the server what the client wants it to do. It is just enough for us to know for now that the GET method means that the client wants to fetch some resource on the server. We then continue to read all other lines which have a header each in them. We break the while (1) loop when we read an empty line, which means that the client is done sending us the request headers. We then call handle_http_method(), passing to it method_buffer, which has the main part of the request, the request verb and the resource path that we are interested in.
void handle_http_method(char *method_buffer, int client_socket)
{
char *method, *path;
method = strtok(method_buffer, " ");
strtolower(method);
path = strtok(NULL, " ");
if (strcmp(method, "get") == 0)
{
handle_get_method(path, client_socket);
}
else if (strcmp(method, "post") == 0) {
handle_post_method(path, client_socket);
}
else
{
handle_unimplemented_method(client_socket);
}
}
The handle_http_method() function breaks up the line into tokens. Meaning, we break up the words separated by spaces. We compare the first word to “get” after converting it to lower case. This it the HTTP method we talked about previously. Although HTTP has several methods or verbs like GET, POST, DELETE, etc, ZeroHTTPd deals only with GET and POST and nothing else. If we don’t see a GET or a POST, then we tell the client we can’t handle that method. If we do see a GET or a POST indeed, we call the handle_get_method() or the handle_post_method() function respectively with the path specified in the header. In the curl example discussed above, the path, if you recall was /, which is the index.
void handle_get_method(char *path, int client_socket)
{
char final_path[1024];
if (handle_app_get_routes(path, client_socket) == METHOD_HANDLED)
return;
/*
If a path ends in a trailing slash, the client probably wants the index
file inside of that directory.
*/
if (path[strlen(path) - 1] == '/')
{
strcpy(final_path, "public");
strcat(final_path, path);
strcat(final_path, "index.html");
}
else
{
strcpy(final_path, "public");
strcat(final_path, path);
}
/* The stat() system call will give you information about the file
* like type (regular file, directory, etc), size, etc. */
struct stat path_stat;
if (stat(final_path, &path_stat) == -1)
{
printf("404 Not Found: %s\n", final_path);
handle_http_404(client_socket);
}
else
{
/* Check if this is a normal/regular file and not a directory or something else */
if (S_ISREG(path_stat.st_mode))
{
send_headers(final_path, path_stat.st_size, client_socket);
transfer_file_contents(final_path, client_socket, path_stat.st_size);
printf("200 %s %ld bytes\n", final_path, path_stat.st_size);
}
else
{
handle_http_404(client_socket);
printf("404 Not Found: %s\n", final_path);
}
}
}
The first check is to see if the path component of the URL points to an “app” in ZeroHTTPd. For example, the Guestbook app is part of ZeroHTTPd. We call handle_app_get_routes()in the beginning and if that function returns METHOD_HANDLED, it means that a client response was sent. There is no need to carry on further with the request. So, we promptly return. Otherwise, we continue on to see if there are any static files we can serve. We discuss handle_app_get_routes()a bit later.
For ZeroHTTPd, all files it serves live inside the public folder. That folder in turn can contain other other sub folder hierarchies. If the request path ends in a /, then ZeroHTTPd looks for an index.html file inside that path. If no file is found, then a HTTP 404 is sent to the client along with a simple message. In HTTP, a status code of 200 means everything went well. In our curl example, you saw that we requested the path /. In this case, ZeroHTTPd serves up the file public/index.html. Once the path is constructed, we use the stat() system call to check if the file exists and we also retrieve its size, which we will use in the content-length header that we send as part of the response. From the same system call, we are also able to determine if the specified path is a regular file or a directory, and when we see that it is a directory, we check if there is an index file present. Since there is no way to “view” a directory, some web servers show a list of files in the directory path requested. You could take that up as an exercise. If we don’t find the file requested, we return an HTTP 404 status.
When we do find a file, we call send_headers() and then transfer_file_contents(). Finally, we print a log message. The send_headers() function is fairly simple to understand.
void send_headers(const char *path, off_t len, int client_socket) {
char small_case_path[1024];
char send_buffer[1024];
strcpy(small_case_path, path);
strtolower(small_case_path);
strcpy(send_buffer, "HTTP/1.0 200 OK\r\n");
send(client_socket, send_buffer, strlen(send_buffer), 0);
strcpy(send_buffer, SERVER_STRING);
send(client_socket, send_buffer, strlen(send_buffer), 0);
/*
* Check the file extension for certain common types of files
* on web pages and send the appropriate content-type header.
* Since extensions can be mixed case like JPG, jpg or Jpg,
* we turn the extension into lower case before checking.
* */
const char *file_ext = get_filename_ext(small_case_path);
if (strcmp("jpg", file_ext) == 0)
strcpy(send_buffer, "Content-Type: image/jpeg\r\n");
if (strcmp("jpeg", file_ext) == 0)
strcpy(send_buffer, "Content-Type: image/jpeg\r\n");
if (strcmp("png", file_ext) == 0)
strcpy(send_buffer, "Content-Type: image/png\r\n");
if (strcmp("gif", file_ext) == 0)
strcpy(send_buffer, "Content-Type: image/gif\r\n");
if (strcmp("htm", file_ext) == 0)
strcpy(send_buffer, "Content-Type: text/html\r\n");
if (strcmp("html", file_ext) == 0)
strcpy(send_buffer, "Content-Type: text/html\r\n");
if (strcmp("js", file_ext) == 0)
strcpy(send_buffer, "Content-Type: application/javascript\r\n");
if (strcmp("css", file_ext) == 0)
strcpy(send_buffer, "Content-Type: text/css\r\n");
if (strcmp("txt", file_ext) == 0)
strcpy(send_buffer, "Content-Type: text/plain\r\n");
send(client_socket, send_buffer, strlen(send_buffer), 0);
/* Send the content-length header, which is the file size in this case. */
sprintf(send_buffer, "content-length: %ld\r\n", len);
send(client_socket, send_buffer, strlen(send_buffer), 0);
/*
* When the browser sees a '\r\n' sequence in a line on its own,
* it understands there are no more headers. Content may follow.
* */
strcpy(send_buffer, "\r\n");
send(client_socket, send_buffer, strlen(send_buffer), 0);
}
We first send HTTP/1.0 200 OK, which tells the client that everything went well and the resource was found. Then, we send a server string header, which identifies the type of server. Then, based on the file extension, we send the content-type header. After that, we send the content-length header with the content length we get from the stat() system call. Finally, we send \r\n on a line by their own signaling the client that we are done sending headers and the content will now follow. On the same socket, we now send the file contents with the transfer_file_contents() function.
void transfer_file_contents(char *file_path, int client_socket, off_t file_size)
{
int fd;
fd = open(file_path, O_RDONLY);
sendfile(client_socket, fd, NULL, file_size);
close(fd);
}
In general, to transfer or copy a file, we read chunks of the source into a buffer, then write that chunk to the destination file or socket and repeat this until the source file is completely read. This is an extremely common operation. However, reading a file means transferring data to user space and writing a file means copying data from user space back to kernel space. These are expensive operations and involve multiple context switches since we’re making calls to read() and write(), too. Because this is a common operation, the kernel guys came up with the sendfile() system call that just takes 2 file descriptors, an offset and length to copy and does the whole copy operation right in the kernel without the buffer copy operations to user space and back while also avoiding the multiple context switches caused due to making system calls. We use sendfile() to immensely simplify the data transfer operation to the client socket.
This ends the processing of the client request. We now close the client socket in the enter_server_loop() function right after handle_client() returns.
While we were processing the client request–that is we were parsing the HTTP headers to get the path, and if everything went well, we used sendfile() to transfer the requested file over the client socket–if our iterative server got any more client connections, those connections would be queued for accept() to retrieve them. This is why our server is even called the iterative server. It handles clients one after the other and cannot server clients in parallel. In real-life, though, any popular service will see more than one user concurrently. And if each request were to take time to serve, it makes the waiting time even longer for clients considering the fact that data also takes time to travel between their browser and the server over the internet. Imagine connecting to a popular website and having to wait for a couple of minutes to see the page load. It is easy to figure out if clients have to wait for the server to process their request or not. If the server is not designed to somehow call accept() and remain blocked on it while it is serving requests from other clients, client requests will queue up. This is the main problem with this iterative server.
Also, if you open the ZeroHTTPd index page in your browser by going to http://localhost:8000, you can see what we have an image there as well. Once the HTML file is transferred to the browser, the browser then parses it and figures out which other files referenced in the HTML file it needs to load from the server. These requests also hit our server. These are also processed one after the other. When you are the only person connected to this server, you’ll certainly feel it serves up content pretty fast, but you should really imagine hundreds of clients connected to this server and now that you know and understand how the server is structured, you should be able to appreciate why this server architecture will not perform well at all.
The Guestbook App
While we’ve seen how ZeroHTTPd serves static files, we will now see how it serves the Guestbook “app”, which is really an HTML page with some dynamic content. Take a look at the annotated screenshot below:
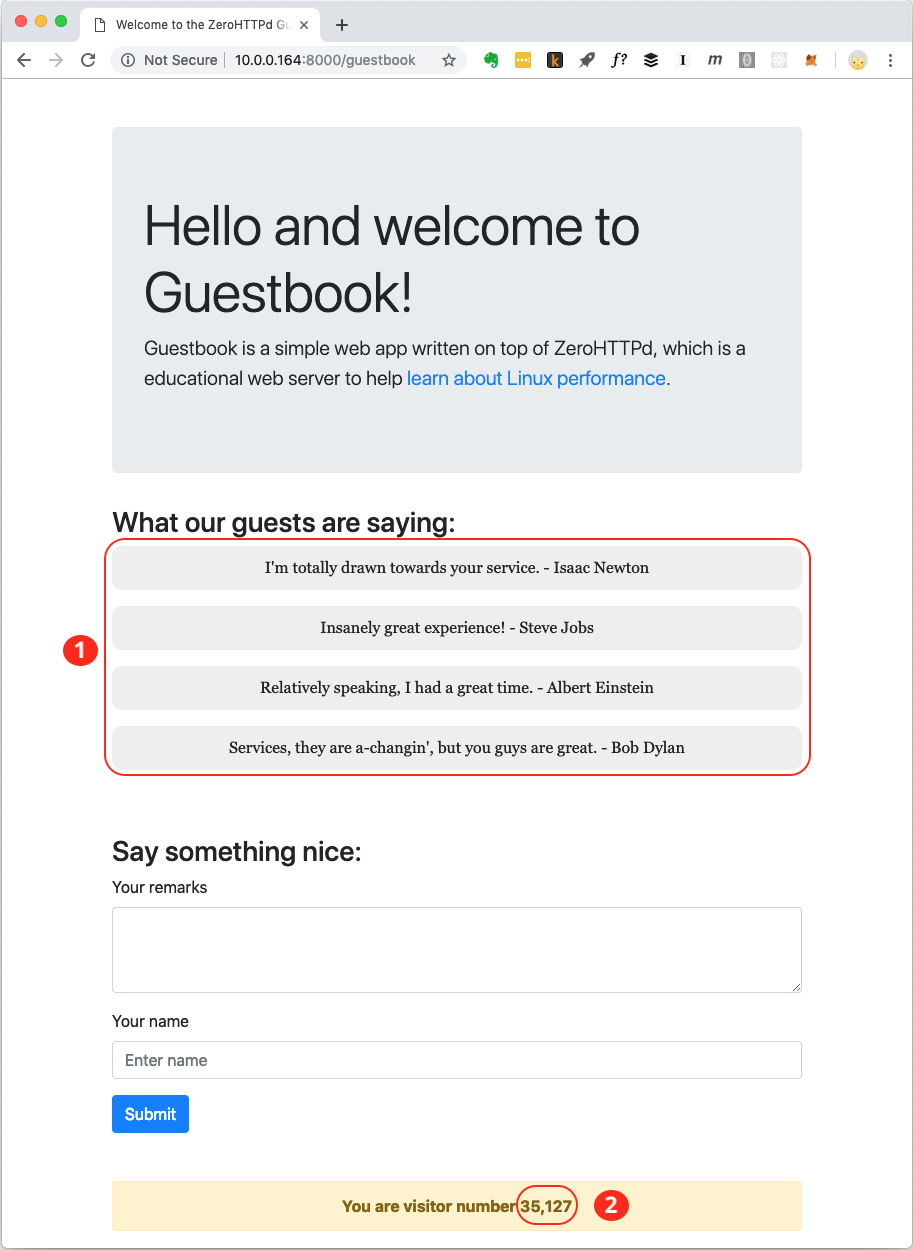
This resulting HTML page you see in the screenshot above is constructed from what we call a “template”. That template is really a regular HTML page which you can take a look at in templates/guestbook/index.html. While more sophisticated web frameworks allow you to use specialized language snippets as part of view templates, in ZeroHTTPd, we place special strings we call variables at locations that we want to insert dynamic content into, build HTML snippets for that dynamic content at runtime and replace the variables with the dynamic HTML snippets. For example, in the screenshot above, each guestbook entry is an HTML <p>tag. The section labeled “1” contains guestbook entries. Once we have data from Redis, we create as many tags as there are entries in Redis and replace the variable $GUEST_REMARKS$with the <p>tags we generate. As for the visitor count at the bottom of the page, labeled with a “2”, we replace the variable in the template $VISITOR_COUNT$ with the value of the key we get from Redis. We will see the function render_guestbook_template() in more detail below.
Routing
In many web frameworks, you get a lot of help calling specific pieces of your code in response to the path in the URL. This functionality is called routing. Popular web frameworks help route the request to the right request handling code based on the request path. In ZeroHTTPd, this is done by a simple function, handle_app_get_routes(). This function gets the path component of the URL as an argument and checks to see if it is a path we need to handle specially. Currently, the only check it performs is to see if the path matches /guestbook and calls the render_guestbook_template()function to handle the real work. It returns METHOD_HANDLED to signal that it took care of responding to the client so that the calling function, in this case handle_get_method()refrains from sending any more responses to the client.
If you were to extend ZeroHTTPd to handle more dynamic content, you’ll begin by checking for the path of your interest in handle_app_get_routes()and calling the appropriate handler function.
Rendering the Guestbook template
As described previously, the render_guestbook_template()takes care of getting the information from Redis, replacing the variables in the template file with the dynamic content created and writing it to the client socket.
int render_guestbook_template(int client_socket) {
char templ[16384]="";
char rendering[16384]="";
/* Read the template file */
int fd = open(GUESTBOOK_TEMPLATE, O_RDONLY);
if (fd == -1)
fatal_error("Template read()");
read(fd, templ, sizeof(templ));
close(fd);
/* Get guestbook entries and render them as HTML */
int entries_count;
char **guest_entries;
char guest_entries_html[16384]="";
redis_get_list(GUESTBOOK_REDIS_REMARKS_KEY, &guest_entries, &entries_count);
for (int i = 0; i < entries_count; i++) {
char guest_entry[1024];
sprintf(guest_entry, "<p class=\"guest-entry\">%s</p>", guest_entries[i]);
strcat(guest_entries_html, guest_entry);
}
redis_free_array_result(guest_entries, entries_count);
/* In Redis, increment visitor count and fetch latest value */
int visitor_count;
char visitor_count_str[16]="";
redis_incr(GUESTBOOK_REDIS_VISITOR_KEY);
redis_get_int_key(GUESTBOOK_REDIS_VISITOR_KEY, &visitor_count);
sprintf(visitor_count_str, "%'d", visitor_count);
/* Replace guestbook entries */
char *entries = strstr(templ, GUESTBOOK_TMPL_REMARKS);
if (entries) {
memcpy(rendering, templ, entries-templ);
strcat(rendering, guest_entries_html);
char *copy_offset = templ + (entries-templ) + strlen(GUESTBOOK_TMPL_REMARKS);
strcat(rendering, copy_offset);
strcpy(templ, rendering);
bzero(rendering, sizeof(rendering));
}
/* Replace visitor count */
char *vcount = strstr(templ, GUESTBOOK_TMPL_VISITOR);
if (vcount) {
memcpy(rendering, templ, vcount-templ);
strcat(rendering, visitor_count_str);
char *copy_offset = templ + (vcount-templ) + strlen(GUESTBOOK_TMPL_VISITOR);
strcat(rendering, copy_offset);
strcpy(templ, rendering);
bzero(rendering, sizeof(rendering));
}
/*
* We've now rendered the template. Send headers and finally the
* template over to the client.
* */
char send_buffer[1024];
strcpy(send_buffer, "HTTP/1.0 200 OK\r\n");
send(client_socket, send_buffer, strlen(send_buffer), 0);
strcpy(send_buffer, SERVER_STRING);
send(client_socket, send_buffer, strlen(send_buffer), 0);
strcpy(send_buffer, "Content-Type: text/html\r\n");
send(client_socket, send_buffer, strlen(send_buffer), 0);
sprintf(send_buffer, "content-length: %ld\r\n", strlen(templ));
send(client_socket, send_buffer, strlen(send_buffer), 0);
strcpy(send_buffer, "\r\n");
send(client_socket, send_buffer, strlen(send_buffer), 0);
send(client_socket, templ, strlen(templ), 0);
printf("200 GET /guestbook %ld bytes\n", strlen(templ));
}
We start by opening the template file. We then call redis_get_list() on line #16 to get guestbook entries which are stored in a Redis list. Once we have that list, which we have as an array, in the loop in lines 17-21, we form the HTML code snippet that holds the p tags that make up the guestbook entries. In line #22, we call redis_free_array_result() which is a utility function to free all the memory allocated by redis_get_list(). In line #27, we call redis_incr()to increment the Redis key value that tracks the visitor count. In line #28, we call redis_get_int_key(), which fetches a key from Redis and converts it to an integer value. Now that we have the bits of information we need, in code between lines 31 and 51, we replace the variable strings in the template with the dynamic content based on the information we have in Redis. In line 58-69, we send headers and the modified template to the client.
Done!
In the next part, we will look at serving each client with a child process of its own, while the parent process immediately goes back to blocking on accept(), which means that new client connections can be accepted and served without having to wait.
Comments
6 responses to “Linux Applications Performance: Part I: Iterative Servers”
[…] Part I. Iterative Servers […]
[…] Part I. Iterative Servers […]
[…] Part I. Iterative Servers […]
[…] Part I. Iterative Servers […]
[…] Part I. Iterative Servers […]
[…] Part I. Iterative Servers […]