They are popular and they are misunderstood. Containers have become the default way applications are packaged and run on servers, initially popularized by Docker. Now, Docker itself is misunderstood. It is the name of a company and a command (a suite of commands, rather) that allow you to manage containers (create, run, delete, network) easily. Containers themselves however, are created from a set of operating system primitives. In this article, we shall concern ourselves with containers on the Linux operating system and simply act as though containers on Windows do not exist at all.
There is no single system call under Linux that creates containers. They are a loose construct made by utilizing Linux namespaces and control groups or cgroups.
What is Gocker?
Gocker is an implementation from scratch of the core functionalities of Docker in the Go programming language. The main aim here is to provide an understanding of how exactly containers work at the Linux system call level. Gocker allows you to create containers, manage container images, execute processes in existing containers, etc.
Gocker capabilities
Gocker can emulate the core of Docker, letting you manage Docker images (which it gets from Docker Hub), run containers, list running containers or execute a process in an already running container:
- Run a process in a container
gocker run <--cpus=cpus-max> <--mem=mem-max> <--pids=pids-max> <image[:tag]> </path/to/command>
- List running containers
gocker ps
- Execute a process in a running container
gocker exec </path/to/command>
- List locally available images
gocker images
- Remove a locally available image
gocker rmi
Other capabilities
- Gocker uses the Ovelay file system to create containers quickly without the need to copy whole file systems while also sharing the same container image between multiple container instances.
- Gocker containers get their own networking namespace and are able to access the internet. See limitations below.
- You can control system resources like CPU percentage, the amount of RAM and the number of processes. Gocker achieves this by leveraging cgroups.
Gocker container isolation
Containers created with Gocker get the following namespaces of their own (see run.go and network.go):
- File system (via
chroot) - PID
- IPC
- UTS (hostname)
- Mount
- Network
While cgroups to limit the following are created, continers are left to use unlimited resources unless you specify the --mem, --cpus or --pids options to the gocker run command. These flags limit the maximum RAM, CPU cores and PIDs the container can consume respectively.
- Number of CPU cores
- RAM
- Number of PIDs (to limit processes)
Namespaces basics
All Linux machines, as they boot are part of a set of “default” namespaces. Processes created on the machine, inherit the default namespaces as well. In other words, processes can see what other processes are running, list network interfaces, list mount points, list named IPC objects or files where permissions permit, for example because all the objects exist in the default namespace as well. When a process is created for example, we can tell Linux to create a new PID name space for us, in which case the new process and any of its descendants form a new hierarchy or PIDs with the newly created initial process being PID 1, just like the special init process is on a Linux machine. Let’s say a process named “new_child” is created with a new PID namespace. When that process or its descendants use system calls like getpid() or getppid(), they see PIDs from the new name space. For example, new_child, in a newly created PID namespace will get 1 as a result for both these system calls. Whereas, when you look at the PID of new_child from the default namespace, of course you won’t have 1 assigned to it. That would be init in the default namespace. It will be assigned a PID more in line with what series of PIDs processes around the time were being assigned.
The Linux operating system provides ways to create new namespaces as a process is being created or for an existing, running process to associate itself with. All namespaces, irrespective of their type are assigned internal IDs. Namespace is a kind of kernel object. A process can belong only to one namespace, per type of namespace. For example, let’s say a process new_child‘s PID namespace is set to a namespace with internal ID 0x87654321, it can’t belong to another PID namespace. However, there could be other processes that belong to the same PID namespace 0x87654321. Also, descendants of new_child will automatically belong to the same PID namespace. Namespaces are inherited.
You can list various namespaces in your machine using the lsns utility. Even if you aren’t running any containers on your machine, you are very likely to see other processes associated with various namespaces. This goes to show that namespaces do not just have to be used in the context of containers. They can be used anywhere. They provide isolation. They are a great security feature. On modern Linux systems, you will see init, systemd, several system daemons, Chrome, Slack and of course Docker containers using various namespaces. Let’s take a look at a section of the output from the lsns utility on my machine:
NS TYPE NPROCS PID USER COMMAND 4026532281 mnt 1 313 root /usr/lib/systemd/systemd-udevd 4026532282 uts 1 313 root /usr/lib/systemd/systemd-udevd 4026532313 mnt 1 483 systemd-timesync /usr/lib/systemd/systemd-timesyncd 4026532332 uts 1 483 systemd-timesync /usr/lib/systemd/systemd-timesyncd 4026532334 mnt 1 502 root /usr/bin/NetworkManager --no-daemon 4026532335 mnt 1 503 root /usr/lib/systemd/systemd-logind 4026532336 uts 1 503 root /usr/lib/systemd/systemd-logind 4026532341 pid 1 1943 shuveb /opt/google/chrome/nacl_helper 4026532343 pid 2 1941 shuveb /opt/google/chrome/chrome --type=zygote 4026532345 net 50 1941 shuveb /opt/google/chrome/chrome --type=zygote 4026532449 mnt 1 547 root /usr/lib/boltd 4026532489 mnt 1 580 root /usr/lib/bluetooth/bluetoothd 4026532579 net 1 1943 shuveb /opt/google/chrome/nacl_helper 4026532661 mnt 1 766 root /usr/lib/upowerd 4026532664 user 1 766 root /usr/lib/upowerd 4026532665 pid 1 2521 shuveb /opt/google/chrome/chrome --type=renderer 4026532667 net 1 836 rtkit /usr/lib/rtkit-daemon 4026532753 mnt 1 943 colord /usr/lib/colord 4026532769 user 1 1943 shuveb /opt/google/chrome/nacl_helper 4026532770 user 50 1941 shuveb /opt/google/chrome/chrome --type=zygote 4026532771 pid 1 2010 shuveb /opt/google/chrome/chrome --type=renderer 4026532772 pid 1 2765 shuveb /opt/google/chrome/chrome --type=renderer 4026531835 cgroup 294 1 root /sbin/init 4026531836 pid 237 1 root /sbin/init 4026531837 user 238 1 root /sbin/init 4026531838 uts 289 1 root /sbin/init 4026531839 ipc 292 1 root /sbin/init 4026531840 mnt 283 1 root /sbin/init 4026531992 net 236 1 root /sbin/init 4026532912 pid 2 3249 shuveb /usr/lib/slack/slack --type=zygote 4026532914 net 2 3249 shuveb /usr/lib/slack/slack --type=zygote 4026533003 user 2 3249 shuveb /usr/lib/slack/slack --type=zygote
Even if you do not explicitly create namespaces, processes will be part of a default namespace. Details of all namespaces are recorded in the /proc file system. You can see the namespaces your shell’s process belongs to by typing in ls -l /proc/self/ns/. Here are the results from mine. Also, these are mostly inherited from init:
➜ ~ ls -l /proc/self/ns total 0 lrwxrwxrwx 1 shuveb shuveb 0 Jun 13 11:44 cgroup -> 'cgroup:[4026531835]' lrwxrwxrwx 1 shuveb shuveb 0 Jun 13 11:44 ipc -> 'ipc:[4026531839]' lrwxrwxrwx 1 shuveb shuveb 0 Jun 13 11:44 mnt -> 'mnt:[4026531840]' lrwxrwxrwx 1 shuveb shuveb 0 Jun 13 11:44 net -> 'net:[4026531992]' lrwxrwxrwx 1 shuveb shuveb 0 Jun 13 11:44 pid -> 'pid:[4026531836]' lrwxrwxrwx 1 shuveb shuveb 0 Jun 13 11:44 pid_for_children -> 'pid:[4026531836]' lrwxrwxrwx 1 shuveb shuveb 0 Jun 13 11:44 user -> 'user:[4026531837]' lrwxrwxrwx 1 shuveb shuveb 0 Jun 13 11:44 uts -> 'uts:[4026531838]'
Namespaces without containers
From the output of lsns, we see that containers aren’t the only objects that use namespaces. To that end, let’s create an instance of a shell with its own PID namespace. We’ll be using the unshare utility to do that. The name “unshare” is telling. There is also a Linux system call by the same name that lets you un-share the default namespace, making the calling process join a newly created one.
➜ ~ sudo unshare --fork --pid --mount-proc /bin/bash [root@kodai shuveb]# ps aux USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 1 0.5 0.0 8296 4944 pts/1 S 08:59 0:00 /bin/bash root 2 0.0 0.0 8816 3336 pts/1 R+ 08:59 0:00 ps aux [root@kodai shuveb]#
In the above invocation, the unshare utility is forking a new process, calling the unshare() system call to create a new PID namespace and then execs /bin/bash in it. We also tell the unshare utility to mount the proc file system in the new process. This is where the ps utility gets its information from. From the output of the ps command, you can indeed see that this shell has a new PID namespace where it is PID 1 and since the ps is started by a shell that has a new PID namespace, it inherits it and gets a PID of 2. As an exercise, you can figure out what PID the shell process running in this container has on the host.
Types of namespaces
With our understanding of the PID namespace, let’s try and understand what other namespaces are there and what they mean. The namespaces man page talks about 8 different namespaces. Here are the different types with a short description along with links to relevant man pages:
Namespace Flag Isolates Cgroup CLONE_NEWCGROUP Cgroup root directory IPC CLONE_NEWIPC System V IPC,POSIX message queues Network CLONE_NEWNET Network devices,stacks, ports, etc. Mount CLONE_NEWNS Mount points PID CLONE_NEWPID Process IDs Time CLONE_NEWTIME Boot and monotonic clocks User CLONE_NEWUSER User and group IDs UTS CLONE_NEWUTS Hostname and NIS domain name
You can imagine what you can do with these namespaces for new or existing processes. You can isolate them almost as though they are running in a separate virtual machine, while they are running on the same machine. You can have several processes isolated in their own namespaces, running on the same host kernel. This is a lot more efficient than running several virtual machines.
Creating new namespaces or joining existing ones
By default, when you create a process with fork(), the child inherits the namespaces of the process that calls fork(). What if you wanted the new process being created to be part of a new set of namespaces? As you can see, fork() has exactly 0 arguments and does not allow us to control the child’s properties before it is created. You can however exert that kind of control with the clone() system call, which allows for very fine-grained control of the new process it creates.
A side note on clone()
Under Linux, while there are different system calls like fork(), vfork() and clone() to create new processes. Internally though, fork() and vfork() in the kernel simply call clone() with different arguments. The kernel source code around this (with some editing from me for better clarity) is very simple to understand. In the file kernel/fork.c, you can see this:
SYSCALL_DEFINE0(fork)
{
struct kernel_clone_args args = {
.exit_signal = SIGCHLD,
};
return _do_fork(&args);
}
SYSCALL_DEFINE0(vfork)
{
struct kernel_clone_args args = {
.flags = CLONE_VFORK | CLONE_VM,
.exit_signal = SIGCHLD,
};
return _do_fork(&args);
}
SYSCALL_DEFINE5(clone, unsigned long, clone_flags, unsigned long, newsp,
int __user *, parent_tidptr,
int __user *, child_tidptr,
unsigned long, tls)
{
struct kernel_clone_args args = {
.flags = (lower_32_bits(clone_flags) & ~CSIGNAL),
.pidfd = parent_tidptr,
.child_tid = child_tidptr,
.parent_tid = parent_tidptr,
.exit_signal = (lower_32_bits(clone_flags) & CSIGNAL),
.stack = newsp,
.tls = tls,
};
if (!legacy_clone_args_valid(&args))
return -EINVAL;
return _do_fork(&args);
}
As you can see, all these three system calls just call _do_fork() with different arguments. _do_fork() implements the logic of creating a new process.
Using clone() to create processes with new namespaces
Gocker uses the clone() system call via Go’s “exec” package by doing the following. In run.go, which handles stuff related to running a container, you can see this:
cmd = exec.Command("/proc/self/exe", args...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWPID |
syscall.CLONE_NEWNS |
syscall.CLONE_NEWUTS |
syscall.CLONE_NEWIPC,
}
doOrDie(cmd.Run())
In syscall.SysProcAttr, we can pass in Cloneflags, which will then be passed into a call to the clone() system call. The astute reader would have noticed that we are not setting up a separate network namespace here. In Gocker, we setup a virtual Ethernet interface, add it to a new network namespace and have the container join that namespace using a different Linux system call. We’ll discuss this subsequently.
Using unshare() to create and join new namespaces
If you want to create a new namespace for an existing process without having to create a new child process with clone(), Linux provides the unshare() system call.
Joining namespaces other processes belong to
To join namespaces referred to by files or to join namespaces other processes belong to, Linux makes the setns() system call available. This is incredibly useful, as we shall shortly see.
How Gocker creates containers
Some of the logs messages from Gocker have been kept around since the main aim of Gocker is to aid in the understanding Linux containers. In that sense, it is a lot more verbose than running Docker. Let’s look at the logs to guide us about program execution. We can then drill down and see how things actually work:
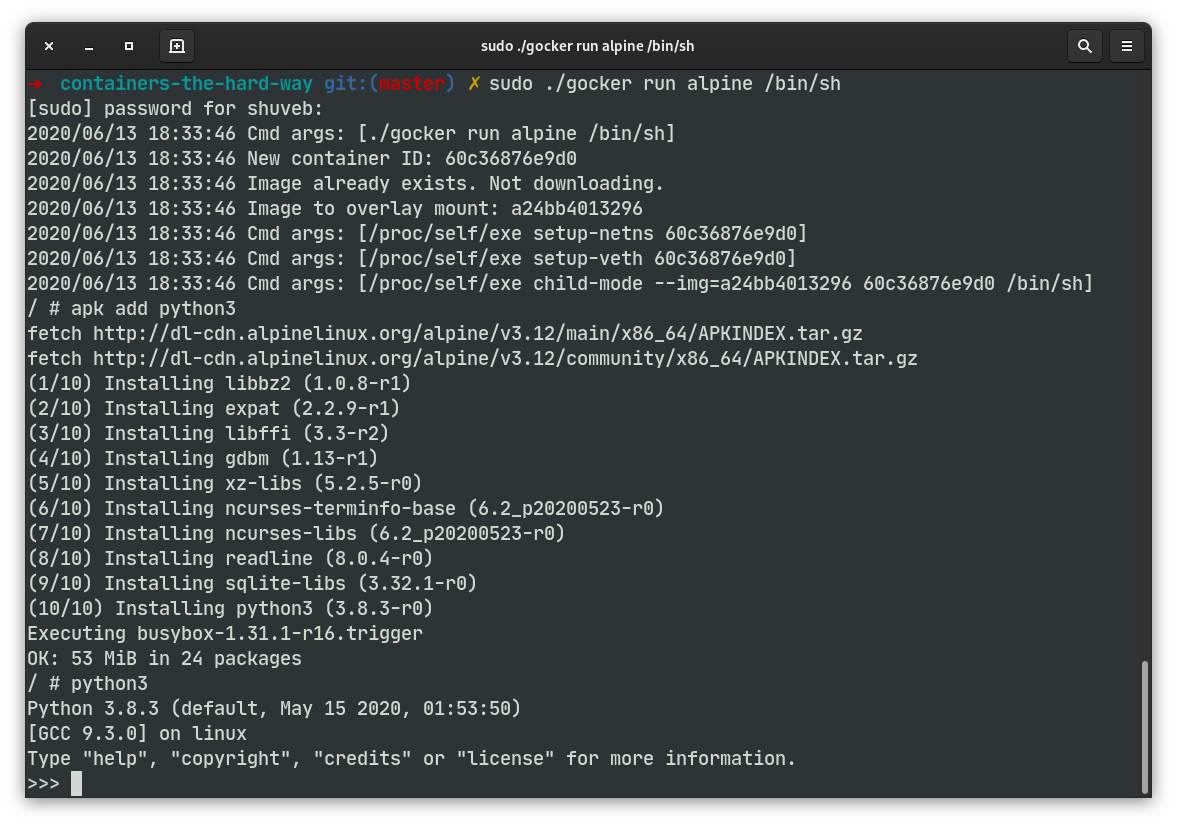
➜ sudo ./gocker run alpine /bin/sh 2020/06/13 12:37:53 Cmd args: [./gocker run alpine /bin/sh] 2020/06/13 12:37:53 New container ID: 33c20f9ee600 2020/06/13 12:37:53 Image already exists. Not downloading. 2020/06/13 12:37:53 Image to overlay mount: a24bb4013296 2020/06/13 12:37:53 Cmd args: [/proc/self/exe setup-netns 33c20f9ee600] 2020/06/13 12:37:53 Cmd args: [/proc/self/exe setup-veth 33c20f9ee600] 2020/06/13 12:37:53 Cmd args: [/proc/self/exe child-mode --img=a24bb4013296 33c20f9ee600 /bin/sh] / #
Here, we’re asking Gocker to run a shell from the Alpine Linux image. We’ll see later how images are managed. For now, pay attention to the log lines that start with “Cmd args:”. This line means a new process was spawned. The first log line shows us the process our shell starts as a result of us running the Gocker command. Towards the end however, we see three more processes started. The final one with the 2nd argument as “child-mode” is the one that executes the shell, /bin/sh that we ask for inside of an Alpine Linux image. Before that, we see two other processes with the arguments “setup-netns” and “setup-veth” respectively. These processes setup a new network namespace and setup the container end of a virtual Ethernet device pair that lets the container talk to the outside world respectively.
For various reasons, the Go language does not directly support the fork() system call. We work around this limitation by creating a new process, but executing the current program again in it. The path to the currently running executable is pointed to by /proc/self/exe. We pass different command line parameters to call the appropriate function (which we would have called when fork() had returned in the child process) depending on the command line argument.
Organization of the source code
The Gocker source code is organized in files by command like argument. For example, functions that primarily serve the gocker run command line argument are in the run.go file. Similarly, functions primarily required for gocker exec are in the exec.go file. This does not mean that these files are self-contained. They freely call functions from other files. There are also files that implement common functionality like cgroups.go and utils.go.
Running a container
In main.go, you can see that if the Gocker command is run, we check to ensure that the gocker0 bridge is up and running. Else, we start it by calling setupGockerBridge() which does the job. Finally we call the function initContainer(), which is implemented in run.go. Let’s take a look at that function closely:
func initContainer(mem int, swap int, pids int, cpus float64,
src string, args []string) {
containerID := createContainerID()
log.Printf("New container ID: %s\n", containerID)
imageShaHex := downloadImageIfRequired(src)
log.Printf("Image to overlay mount: %s\n", imageShaHex)
createContainerDirectories(containerID)
mountOverlayFileSystem(containerID, imageShaHex)
if err := setupVirtualEthOnHost(containerID); err != nil {
log.Fatalf("Unable to setup Veth0 on host: %v", err)
}
prepareAndExecuteContainer(mem, swap, pids, cpus, containerID,
imageShaHex, args)
log.Printf("Container done.\n")
unmountNetworkNamespace(containerID)
unmountContainerFs(containerID)
removeCGroups(containerID)
os.RemoveAll(getGockerContainersPath() + "/" + containerID)
}
First, we create a unique container ID by calling createContainerID(). Then we call downloadImageIfRequired() so that the container image can be downloaded from Docker Hub if it is not already available locally. Gocker uses sub directories within /var/run/gocker/containers to mount container root file systems. createContainerDirectories() takes care of that. mountOverlayFileSystem() knows how to deal with multi-layer Docker images and mounts a merged file system for an available image on /var/run/gocker/containers/<container-id>/fs/mnt. While this might seem daunting, this is not all that difficult to understand if you read the source code. Overlay file systems allow you to create a stacked file system where the lower layers, in this case from Docker root file systems, are read-only while any changes are saved to an “upperdir” without changing any files in the lower layers. This allows many containers to share a single Docker image. When we say “image” in a virtual machine context, it generally refers to a disk image. But here, it is just a directory or a set of directories ( fancy name: layers), with files that make up the root file system of a Docker “image” which can be mounted using an Overlay file system to create the root file system for a new container.
Next, we create a virtual Ethernet paired device, which is much like a pipe with a call to setupVirtualEthOnHost(). These take the form of name veth0_<container-id> and veth1_<container-id>. We connect veth0 part of the pair to our bridge, gocker0 on the host. Later, we will use veth1 part of the pair inside the container. This pair is like a pipe and is the secret to network communication from within containers which have their own network namespace. We’ll subsequently cover how we setup the veth1 part inside the container.
Finally, prepareAndExecuteContainer() is called which actually executes the process in a container. When this function returns, the container has done executing. Lastly, we then do some cleanup and exit. Let’s look at what prepareAndExecuteContainer() does. It essentially create the 3 processes for which we saw logs, running the same gocker binary with the arguments setup-netns, setup-veth and child-mode.
Setting up networking that works inside containers
Setting up a new networking namespace is super easy. You just include CLONE_NEWNET as part of the flags bit mask that’s passed on to the clone() system call. What’s tricky is ensuring a container can have a network interface inside it via which it can communicate to the outside. In Gocker, the very first new namespace we create is that of the network. This happens when gocker is called with setup-ns and setup-veth arguments. First, we setup a new networking namespace. The setns() system call can set the calling process’ namespace to one referred by a file descriptor that points to a file in /proc/<pid>/ns, which lists all namespaces a process belongs to. Let’s take a look at the setupNewNetworkNamespace() function which is called as the result of gocker being invoked as a result of it being called with the setup-netns argument.
func setupNewNetworkNamespace(containerID string) {
_ = createDirsIfDontExist([]string{getGockerNetNsPath()})
nsMount := getGockerNetNsPath() + "/" + containerID
if _, err := syscall.Open(nsMount,
syscall.O_RDONLY|syscall.O_CREAT|syscall.O_EXCL,
0644); err != nil {
log.Fatalf("Unable to open bind mount file: :%v\n", err)
}
fd, err := syscall.Open("/proc/self/ns/net", syscall.O_RDONLY, 0)
defer syscall.Close(fd)
if err != nil {
log.Fatalf("Unable to open: %v\n", err)
}
if err := syscall.Unshare(syscall.CLONE_NEWNET); err != nil {
log.Fatalf("Unshare system call failed: %v\n", err)
}
if err := syscall.Mount("/proc/self/ns/net", nsMount,
"bind", syscall.MS_BIND, ""); err != nil {
log.Fatalf("Mount system call failed: %v\n", err)
}
if err := unix.Setns(fd, syscall.CLONE_NEWNET); err != nil {
log.Fatalf("Setns system call failed: %v\n", err)
}
}
The Linux kernel automatically removes a namespace whenever the last process that’s part of it terminates. There is a technique however to keep a namespace around by bind mounting it, even if no processes are part of it. In the setupNewNetworkNamespace() function, we use this technique. We first open the processes’s network namespace file, which is in /proc/self/ns/net. We then call the unshare() system call with the CLONE_NEWNET argument. This disassociates the calling process with the namespace it is part of, creates a fresh new network namespace and sets it as the network namespace for the process. We then bind mount the network namespace special file of this process to a known file name, which is /var/run/gocker/net-ns/<container-id>. This file can anytime be used to refer to this network namespace. Now, we can exit this process, but since this process’ new network namespace is bind mounted on to a new file, the kernel will keep this namespace around.
Next, gocker is called with the setup-veth argument. This calls the functions setupContainerNetworkInterfaceStep1() and setupContainerNetworkInterfaceStep2(). In the first function, we look up the veth1_<container-id> interface and set its namespace to the new network namespace we created in the previous step. Now, this interface will no longer be visible from the host. But here is the thing: since it is paired with the veth0_<container-id> interface which is still visible on the host, any process that joins this network namespace can communicate to the host and beyond. The 2nd function adds an IP address to the network interface and sets up the gocker0 bridge as its default gateway device.
Phew! We now have a network interface on the host and another on a new network namespace that can communicate with each other. And since this network namespace can be referred to by a file, we can open this file and join this network namespace anytime with the setns() system call. And, this is exactly what we’ll do.
After this, the prepareAndExecuteContainer() call sets up a new process that runs gocker with the child-mode argument. This is the final process that’ll spawn the command we want to run in the container. Let’s look at the new namespaces that the process that runs child-mode is started with. We already saw this code earlier, but here it is once more:
cmd = exec.Command("/proc/self/exe", args...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWPID |
syscall.CLONE_NEWNS |
syscall.CLONE_NEWUTS |
syscall.CLONE_NEWIPC,
}
doOrDie(cmd.Run())
Here we setup new PID, mount, UTS and IPC name spaces. Remember that we have a new network namespace that can be referred to by a file. We just need to join it. We’ll do that in just a bit. The child-mode process calls the function execContainerCommand(). Here it is:
func execContainerCommand(mem int, swap int, pids int, cpus float64,
containerID string, imageShaHex string, args []string) {
mntPath := getContainerFSHome(containerID) + "/mnt"
cmd := exec.Command(args[0], args[1:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
imgConfig := parseContainerConfig(imageShaHex)
doOrDieWithMsg(syscall.Sethostname([]byte(containerID)), "Unable to set hostname")
doOrDieWithMsg(joinContainerNetworkNamespace(containerID), "Unable to join container network namespace")
createCGroups(containerID, true)
configureCGroups(containerID, mem, swap, pids, cpus)
doOrDieWithMsg(copyNameserverConfig(containerID), "Unable to copy resolve.conf")
doOrDieWithMsg(syscall.Chroot(mntPath), "Unable to chroot")
doOrDieWithMsg(os.Chdir("/"), "Unable to change directory")
createDirsIfDontExist([]string{"/proc", "/sys"})
doOrDieWithMsg(syscall.Mount("proc", "/proc", "proc", 0, ""), "Unable to mount proc")
doOrDieWithMsg(syscall.Mount("tmpfs", "/tmp", "tmpfs", 0, ""), "Unable to mount tmpfs")
doOrDieWithMsg(syscall.Mount("tmpfs", "/dev", "tmpfs", 0, ""), "Unable to mount tmpfs on /dev")
createDirsIfDontExist([]string{"/dev/pts"})
doOrDieWithMsg(syscall.Mount("devpts", "/dev/pts", "devpts", 0, ""), "Unable to mount devpts")
doOrDieWithMsg(syscall.Mount("sysfs", "/sys", "sysfs", 0, ""), "Unable to mount sysfs")
setupLocalInterface()
cmd.Env = imgConfig.Config.Env
cmd.Run()
doOrDie(syscall.Unmount("/dev/pts", 0))
doOrDie(syscall.Unmount("/dev", 0))
doOrDie(syscall.Unmount("/sys", 0))
doOrDie(syscall.Unmount("/proc", 0))
doOrDie(syscall.Unmount("/tmp", 0))
}
Here, we set the container’s host name to the container ID, join the new network namespace we created earlier, create Linux control groups that allow us to control CPU, PID and RAM usage, we join those Cgroups, we copy the host’s DNS resolution file into the container’s file system, do a chroot() to the mounted Overlay file system, mount required file systems for the container to be able to run smoothly, setup the local network interface, setup environment variables as advised by the container image and finally run the command the user wants us to run. This command will now run in a set of new namespaces that allow it to be almost fully isolated from the host. Done!
Restricting container resources
This is another star feature of containers apart from the isolation achieved with namespaces: the ability to restrict the amount of resources a container can consume. Cgroups under Linux are simple and they allow us to do just this. While namespaces are implemented via system calls like unshare(), setns() and clone(), Cgroups are managed by creating directories and writing to files into a virtual file system which is mounted under /sys/fs/cgroup. There are 3 directories created by us per container in the Cgroups virtual file system hierarchy:
/sys/fs/cgroup/pids/gocker/<container-id>/sys/fs/cgroup/cpu/gocker/<container-id>/sys/fs/cgroup/mem/gocker/<container-id>
For each created directory, the kernel adds various files that allow that cgroup to be configured automatically.
This is how we configure containers:
- When a container starts, we create 3 directories, one each for the three cgroups we care about: CPU, PIDs and Memory.
- We then set limits for the cgroup by writing to files inside of this directory. For example, to set the maximum number of PIDs allowed in a container, we write that maximum number to
/sys/fs/cgroup/pids/gocker/<cont-id>/pids.max. This configures this Cgroup. - We can now add processes that need to be governed by this Cgroup by adding their PIDs to
/sys/fs/cgroup/pids/gocker/<cont-id>/cgroup.procs.
That is all there is to it. Once you add a process to be governed by a Cgroup, PIDs of all of the processes’ descendants are added to the appropriate Cgroup’s cgroup.procs file automatically by the kernel. Since we start a process in the container that is added to all 3 Cgroups and that process is the usual way other processes are started by the container, all restrictions are inherited by them as well.
Restricting CPU
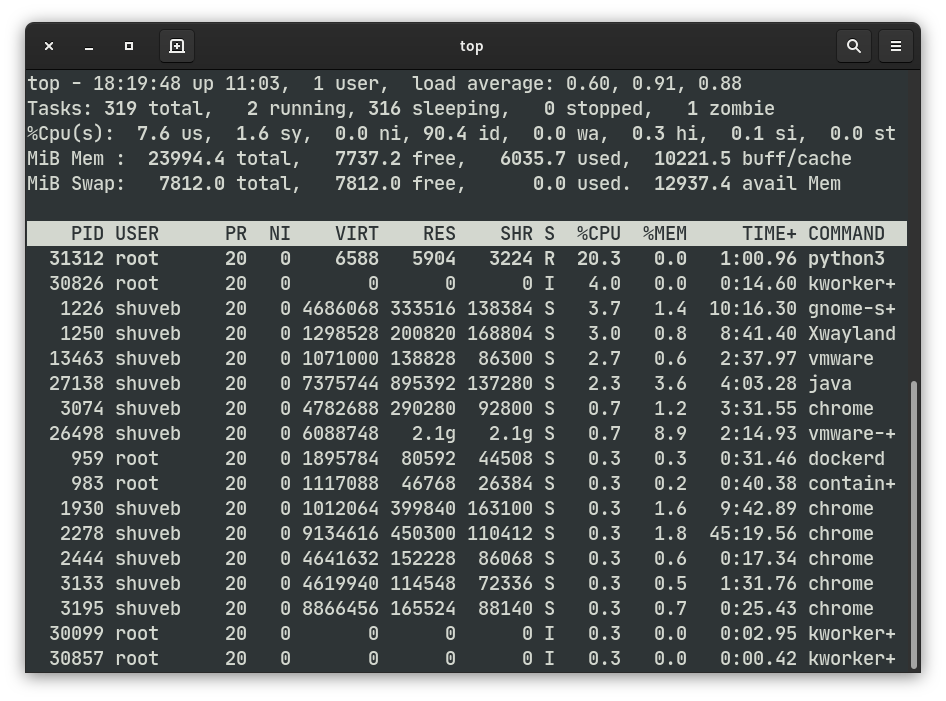
Let’s try restricting the CPU that a container can use to 20% of 1 CPU core of the host system. Let’s start a container with this restriction, install Python and run a tight while loop. We do this by passing gocker the --cpu=0.2 flag:
sudo ./gocker run --cpus=0.2 alpine /bin/sh 2020/06/13 18:14:09 Cmd args: [./gocker run --cpus=0.2 alpine /bin/sh] 2020/06/13 18:14:09 New container ID: d87d44b4d823 2020/06/13 18:14:09 Image already exists. Not downloading. 2020/06/13 18:14:09 Image to overlay mount: a24bb4013296 2020/06/13 18:14:09 Cmd args: [/proc/self/exe setup-netns d87d44b4d823] 2020/06/13 18:14:09 Cmd args: [/proc/self/exe setup-veth d87d44b4d823] 2020/06/13 18:14:09 Cmd args: [/proc/self/exe child-mode --cpus=0.2 --img=a24bb4013296 d87d44b4d823 /bin/sh] / # apk add python3 fetch http://dl-cdn.alpinelinux.org/alpine/v3.12/main/x86_64/APKINDEX.tar.gz fetch http://dl-cdn.alpinelinux.org/alpine/v3.12/community/x86_64/APKINDEX.tar.gz (1/10) Installing libbz2 (1.0.8-r1) (2/10) Installing expat (2.2.9-r1) (3/10) Installing libffi (3.3-r2) (4/10) Installing gdbm (1.13-r1) (5/10) Installing xz-libs (5.2.5-r0) (6/10) Installing ncurses-terminfo-base (6.2_p20200523-r0) (7/10) Installing ncurses-libs (6.2_p20200523-r0) (8/10) Installing readline (8.0.4-r0) (9/10) Installing sqlite-libs (3.32.1-r0) (10/10) Installing python3 (3.8.3-r0) Executing busybox-1.31.1-r16.trigger OK: 53 MiB in 24 packages / # python3 Python 3.8.3 (default, May 15 2020, 01:53:50) [GCC 9.3.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> while True: ... pass ...
Let’s run top on the host and see how much CPU that python process running inside of the container is taking up.
From another terminal, let’s use the gocker exec command to start another python process inside the same container and run a while loop there as well.
➜ sudo ./gocker ps 2020/06/13 18:21:10 Cmd args: [./gocker ps] CONTAINER ID IMAGE COMMAND d87d44b4d823 alpine:latest /usr/bin/python3.8 ➜ sudo ./gocker exec d87d44b4d823 /bin/sh 2020/06/13 18:21:24 Cmd args: [./gocker exec d87d44b4d823 /bin/sh] / # python3 Python 3.8.3 (default, May 15 2020, 01:53:50) [GCC 9.3.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> while True: ... pass ...
There are now 2 python processes, which, if left unrestricted, would have consumed 2 full CPU cores if uncontested without being restricted by Cgroups. Let’s now look at the output of the top command on the host:
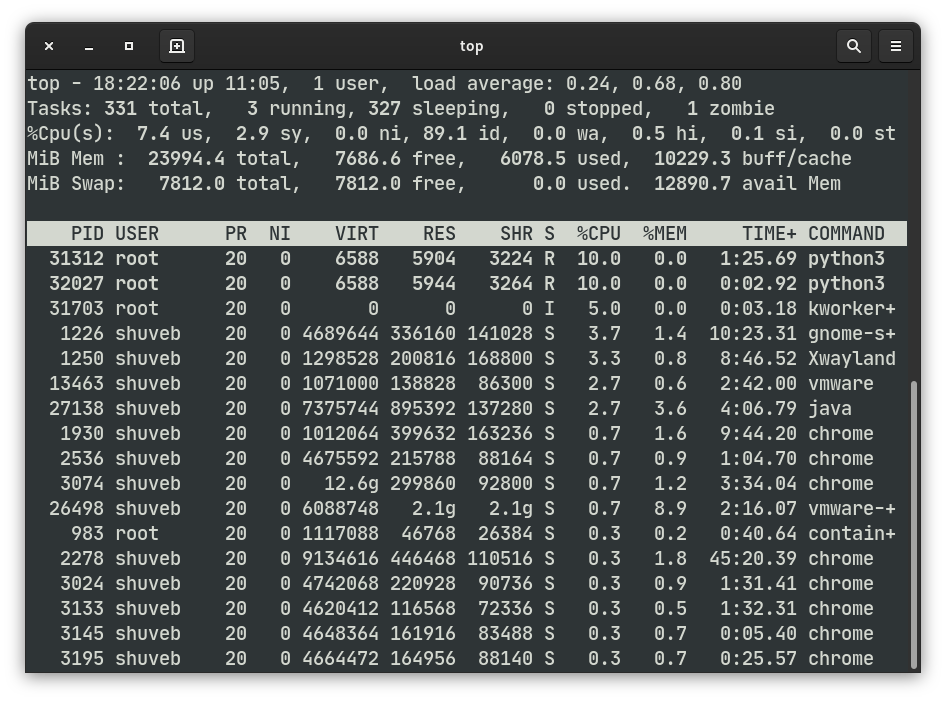
As you can see from the output of the top command from the host, the two python processes, both running tight loops are restricted to 10% CPU each. The container’s 20% CPU quota is being divided by the scheduler among the 2 processes in the container fairly. Please note that it is possible specify the allowance of more than one CPU core as well. For example, if you want to allow a maximum utilization of 2 and a half cores to a container, specify it in the flag as --cpu=2.5.
Restricting PIDs
A container running a shell in a new PID namespace seems to consume 7 PIDs. This means that, if you start a new container with a maximum PIDs limit of 7, you won’t be able start further processes at the shell. Let’s put this to test. [I’m not sure why 7 PIDs are consumed even though there re only 2 processes that are in the running state in the container. This needs further study.]
➜ sudo ./gocker run --pids=7 alpine /bin/sh [sudo] password for shuveb: 2020/06/13 18:28:00 Cmd args: [./gocker run --pids=7 alpine /bin/sh] 2020/06/13 18:28:00 New container ID: 920a577165ef 2020/06/13 18:28:00 Image already exists. Not downloading. 2020/06/13 18:28:00 Image to overlay mount: a24bb4013296 2020/06/13 18:28:00 Cmd args: [/proc/self/exe setup-netns 920a577165ef] 2020/06/13 18:28:00 Cmd args: [/proc/self/exe setup-veth 920a577165ef] 2020/06/13 18:28:00 Cmd args: [/proc/self/exe child-mode --pids=7 --img=a24bb4013296 920a577165ef /bin/sh] / # ls -l /bin/sh: can't fork: Resource temporarily unavailable / #
Restricting RAM
Let’s start a new container with maximum allowed memory set to 128M. We’ll now install python there and allocate a large amount of RAM in there. This should trigger the kernel’s Out-of-memory (OOM) killer, making it kill our python process. Let’s see this in action:
➜ sudo ./gocker run --mem=128 --swap=0 alpine /bin/sh 2020/06/13 18:30:30 Cmd args: [./gocker run --mem=128 --swap=0 alpine /bin/sh] 2020/06/13 18:30:30 New container ID: b22bbc6ee478 2020/06/13 18:30:30 Image already exists. Not downloading. 2020/06/13 18:30:30 Image to overlay mount: a24bb4013296 2020/06/13 18:30:30 Cmd args: [/proc/self/exe setup-netns b22bbc6ee478] 2020/06/13 18:30:30 Cmd args: [/proc/self/exe setup-veth b22bbc6ee478] 2020/06/13 18:30:30 Cmd args: [/proc/self/exe child-mode --mem=128 --swap=0 --img=a24bb4013296 b22bbc6ee478 /bin/sh] / # apk add python3 fetch http://dl-cdn.alpinelinux.org/alpine/v3.12/main/x86_64/APKINDEX.tar.gz fetch http://dl-cdn.alpinelinux.org/alpine/v3.12/community/x86_64/APKINDEX.tar.gz (1/10) Installing libbz2 (1.0.8-r1) (2/10) Installing expat (2.2.9-r1) (3/10) Installing libffi (3.3-r2) (4/10) Installing gdbm (1.13-r1) (5/10) Installing xz-libs (5.2.5-r0) (6/10) Installing ncurses-terminfo-base (6.2_p20200523-r0) (7/10) Installing ncurses-libs (6.2_p20200523-r0) (8/10) Installing readline (8.0.4-r0) (9/10) Installing sqlite-libs (3.32.1-r0) (10/10) Installing python3 (3.8.3-r0) Executing busybox-1.31.1-r16.trigger OK: 53 MiB in 24 packages / # python3 Python 3.8.3 (default, May 15 2020, 01:53:50) [GCC 9.3.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> a1 = bytearray(100 * 1024 * 1024) Killed / #
One thing to note is that we set swap allocated to this container to zero with --swap=0. Without this, while the Cgroup will restrict RAM usage, it will allow the container to use unlimited swap space. When swap is set to zero, the container is restricted absolutely to the amount of RAM allowed in all.
About me
My name is Shuveb Hussain and I’m the author of this Linux-focused blog. You can follow me on Twitter where I post tech-related content mostly focusing on Linux, performance, scalability and cloud technologies.
You must be logged in to post a comment.